Why LEVI?
LEVI discovers algorithms and optimized code using LLMs + evolutionary search. Define a scoring function, set a dollar budget, and walk away.
State-of-the-art results across 7 algorithmic discovery problems, spanning scheduling, forecasting, SQL optimization, and load balancing, at 3–7x lower cost than existing frameworks.
Simple
result = levi.evolve_code(
problem_description="Sort a list of integers as fast as possible",
function_signature="def sort(arr: list[int]) -> list[int]:",
score_fn=lambda fn: score_sorting(fn),
budget_dollars=5.00,
)
No configuration files, no pipeline setup. One function call, one budget. Works with cloud APIs, local models, or both.
3–7x cheaper
90%+ of mutations go through lightweight local models. Frontier models are reserved for infrequent paradigm shifts. $4.50 per problem versus $15–$30 for baselines, saving over $100 across the ADRS suite. More signal per dollar.
Async & parallel
N mutation producers and M evaluation workers run concurrently, connected by an async queue. Neither side blocks the other. Pair this with local models for zero-latency generation, or mix local and cloud in the same run.
Full benchmark results and methodology: ADRS leaderboard.
How It Works
LEVI outperforms leading algorithmic discovery frameworks (OpenEvolve, GEPA, ShinkaEvolve) at up to 1/6th the cost, saving over $100 per problem on a systems benchmark suite. It does this while routing 90%+ of mutations through a local Qwen3-30B model. In controlled comparisons with the same model and budget, LEVI reaches peak performance 12x faster than alternatives.
Code: github.com/ttanv/levi
This section introduces LEVI: an LLM-based evolutionary framework that produces SOTA performances on ADRS problems at a fraction of the cost. It is built on the key insight that too many frameworks assume access to the largest SOTA models, and build their harnesses around them.
Key Insight: Invest in the Harness, Not the Model
Assuming access to the largest models should not be the default. In fact, the original FunSearch paper reported being unable to benefit from larger models, and only with AlphaEvolve did they succeed. The open-source community often misses this, throwing the strongest models at every step.11 OpenEvolve config: uses Claude Opus for mutations.22 ShinkaEvolve (Ye et al, 2025): relies on frontier-scale models throughout the search. LEVI takes a harness-first approach instead, through two key components: stratified model allocation and improved diversity maintenance.
LEVI's architecture: diverse seeds initialize a CVT-MAP-Elites archive; smaller models handle most mutations; a frontier model injects paradigm shifts every K evaluations. Hover over each component for details.
Stratified Model Allocation
Frontier models help, but they are a waste if used for every mutation. Smaller LLMs may actually be preferred under tight budgets, since the sheer quantity of solutions they produce can outweigh the quality advantage of larger models. However, smaller models have a narrower pretraining distribution, limiting their range of ideas and ability to propose fundamentally different approaches. Neither model class is strictly better; they just have different strengths.
Some existing frameworks already support multiple models, but treat them as interchangeable, sampling from an ensemble uniformly or routing calls without regard to what the mutation actually demands. This ignores a natural asymmetry: proposing an entirely new algorithmic direction requires broad knowledge and creative reasoning, while refining an existing approach (adjusting constants, reordering operations, tuning edge cases) requires far less. The harness should be aware of this distinction and allocate accordingly.
LEVI introduces stratified model allocation, which matches model capacity to task demand. Smaller, cheaper models handle the majority of the search: local refinements and incremental improvements within an established algorithmic family. Larger models are reserved for infrequent paradigm shifts: mutations that aim to propose structurally different approaches rather than polish existing ones. The principle is straightforward: allocate each model toward its strength. Small models for breadth and throughput, large models for creative leaps.
However, this raises two questions. First, how do we select representative solutions from each algorithmic family to give the larger model meaningful context for paradigm shifts? Second, since we now rely more heavily on smaller models and their volume of output, we need a more robust mechanism to prevent the archive from converging.
LEVI matches model capacity to task demand: cheap models (e.g. a local Qwen 30B) for refinement, expensive models for paradigm shifts.
Improved Diversity Maintenance
Unifying Structural and Behavioral Diversity. A less obvious reason existing frameworks require frontier models is that those models are doing double duty. Their larger output space implicitly maintains diversity: a GPT-5 or Claude Opus naturally produces a wider spread of solutions than a 30B model, ignoring the fact that the archive itself has no strong mechanism to prevent convergence. When diversity does collapse, the response has been to add complexity on top: ranging from rejection sampling using even more LLM calls to using embedding models. These are compensations for a weak foundation, not solutions to the underlying issue.
The underlying issue is that existing frameworks maintain diversity along only one axis, and a narrow one at that. OpenEvolve considers structural features like code length; GEPA considers per-instance performance trade-offs through Pareto fronts (in practice often more powerful than the former mechanism). Both capture something real, but neither captures the full picture. Structure alone misses behavioral differences: two programs with different loop counts might solve the problem identically. And per-instance scores alone miss solutions that perform similarly on individual instances but work in fundamentally different ways.
Rather than choosing one axis, LEVI uses both as dimensions of a single behavioral descriptor. Each solution is mapped to a fingerprint: a vector combining code-structural features (going beyond simple dimensions like code length to measures such as loop count, cyclomatic complexity) alongside per-instance behavioral results, all normalized and projected to [0, 1]. The framework is also flexible here: users can define their own dimensions when the defaults do not fit their problem.
This fingerprint lives in a CVT-MAP-Elites archive, where a Voronoi tessellation over the combined space maintains geometric structure that neither axis provides alone. The archive holds a diverse set of solutions with different values along the different dimensions. This also directly answers the first question from the previous section: the Voronoi regions naturally cluster solutions into algorithmic families, giving us representative solutions for paradigm shifts.
Archive Initialization. Traditional CVT-MAP-Elites initializes centroids uniformly across the descriptor space. With the higher dimensionality we use (6 to 10 dims), this leads to an extremely sparse tessellation where most regions will never be visited. LEVI adopts a data-driven approach: it creates a set of deliberately unique approaches (regardless of scores) through sequential generation, and then uses those to create the initial centroids. This ensures that the archive is based on solutions that are known to be different.
LEVI maintains diversity through a shared fingerprint space over both structure and behavior, so the archive itself carries more of the diversity burden instead of relying on ever-stronger models or auxiliary heuristics.
ADRS Benchmark Results
We evaluate on the ADRS benchmark suite,33 ADRS (Cheng et al, 2025): benchmark suite from UC Berkeley for LLM-guided optimization on real-world systems problems. a set of real-world systems problems spanning cloud scheduling, load balancing, SQL optimization, and transaction scheduling.
| Framework | Avg | Cloud | EPLB | SQL | Prism | Spot-M | Spot-S | Txn |
|---|---|---|---|---|---|---|---|---|
|
GEPA
|
71.9 | 96.6 | 70.2 | 67.7 | 87.4 | 62.2 | 51.4 | 67.7 |
|
OpenEvolve
|
70.6 | 92.9 | 62.0 | 72.5 | 87.4 | 66.7 | 42.5 | 70.0 |
|
ShinkaEvolve
|
67.4 | 72.0 | 66.4 | 68.5 | 87.4 | 63.6 | 45.6 | 68.2 |
|
LEVI
|
76.5 | 100.0 | 74.6 | 78.3 | 87.4 | 72.4 | 51.7 | 71.1 |
LEVI achieves the highest score on every problem where improvement is possible, with an average of 76.5 compared to 71.9 for the next-best framework (GEPA), a +4.6 point improvement over the prior state of the art. On Cloudcast, LEVI reaches a perfect 100.0, indicating the problem is fully solved under the benchmark’s scoring function. The largest gains appear on LLM-SQL (+5.8) and Spot Multi (+5.7), while more modest improvements on Spot Single (+0.3) and Transaction Scheduling (+1.1) reflect problems with smaller decision spaces or harder optimization landscapes. Prism remains tied at 87.4 across all frameworks, confirming that the current problem formulation admits a single dominant solution.
Cost
LEVI’s stratified allocation is the primary driver of cost reduction. By routing the majority of mutations through lightweight models, the per-generation cost drops by roughly an order of magnitude compared to baselines that use GPT-5 or Gemini-3.0-Pro for every call. This allows LEVI to run substantially more generations while still spending less in total: $4.50 per problem on most tasks (Transaction Scheduling: $13), versus $15 to $30 for baselines.
| Problem | Baseline | LEVI | Savings |
|---|---|---|---|
| Spot Single-Reg | $30 | $4.50 | 6.7x |
| Spot Multi-Reg | $25 | $4.50 | 5.6x |
| LLM-SQL | $20 | $4.50 | 4.4x |
| Cloudcast | $15 | $4.50 | 3.3x |
| Prism | $15 | $4.50 | 3.3x |
| EPLB | $15 | $4.50 | 3.3x |
| Txn Scheduling | $20 | $13 | 1.5x |
The cost reduction is evidence that the harness-first approach works. When the archive maintains diversity, cheap models suffice for most of the search.
Controlled Architecture Comparison
Same model, same budget, three seeds: isolating the search architecture’s contribution.
The main results compare frameworks that differ simultaneously in model choice, budget, and architecture. To isolate the contribution of the search architecture, we run LEVI, OpenEvolve, and GEPA under identical conditions: a single locally-served Qwen3-30B-A3B model, 750 successful evaluations,44 OpenEvolve required reducing parent count from 5 to 2 for the smaller model and still produced many failures. We report successful evaluations rather than total to give OpenEvolve a fair comparison. and three random seeds on two representative problems.
Transaction Scheduling is a variant of an NP-hard ordering problem where multiple algorithmic families (greedy, simulated annealing, genetic) are viable but performance is measured on a single instance, giving Pareto-based diversity no trade-off to exploit. LEVI reaches a score of 62 within the first 100 evaluations, a level neither baseline achieves at any point. Final scores: LEVI 64.9, OpenEvolve 59.9, GEPA 54.4. Both baselines plateau sharply, consistent with early convergence onto a single algorithmic family; LEVI’s curve continues rising past evaluation 500.
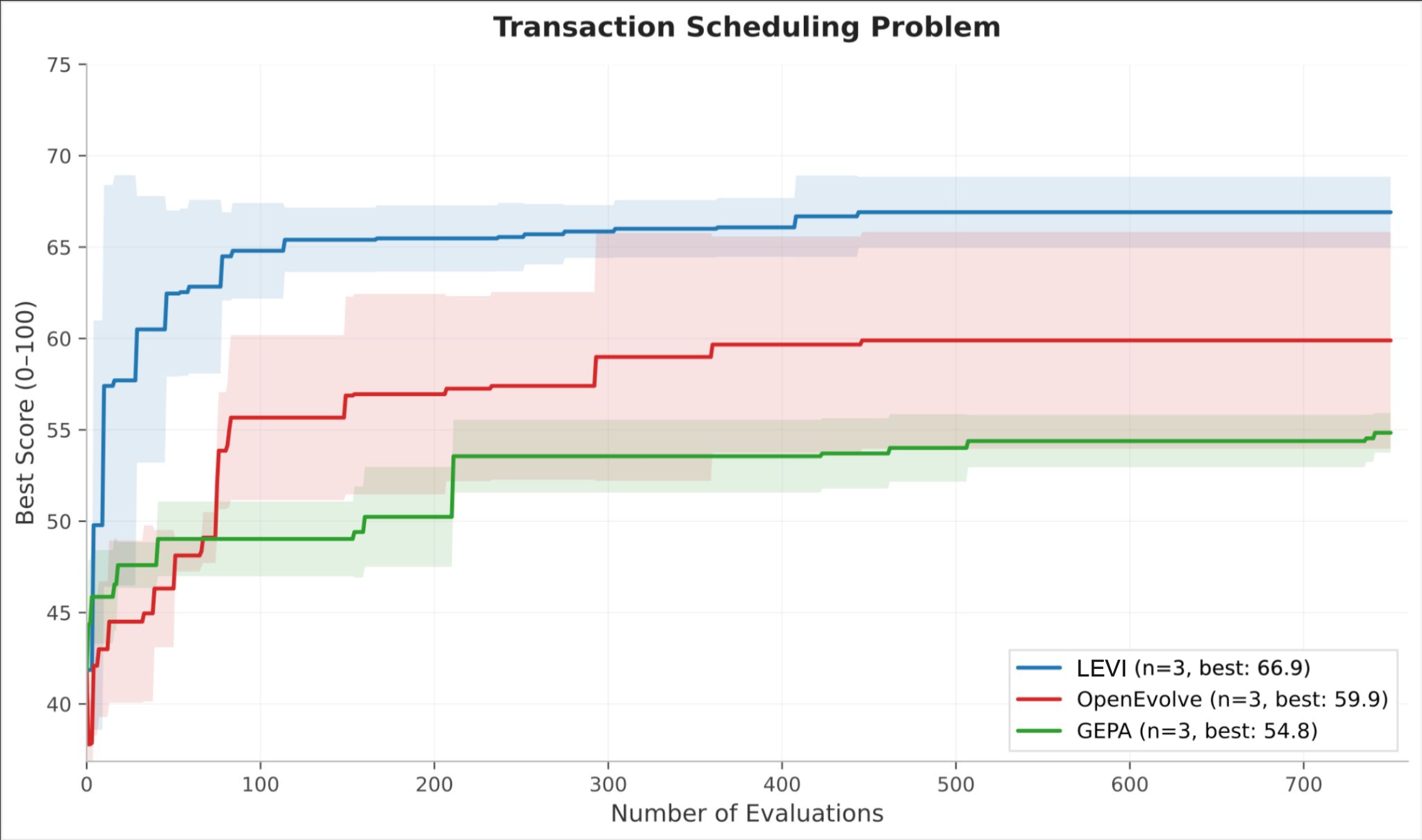
Transaction Scheduling, controlled (Qwen3-30B, 750 evals, 3 seeds). LEVI hits 62 within 100 evals; neither baseline reaches that level at any point.
Can’t Be Late is scored across 1,080 simulations that give Pareto-based approaches a richer signal. The final-score gap narrows (LEVI 44.9, OpenEvolve 43.2, GEPA 37.5), but the efficiency gap widens dramatically. LEVI reaches near-peak performance by roughly evaluation 50, while OpenEvolve requires over 600 evaluations to approach the same level, a roughly 12x advantage in sample efficiency.
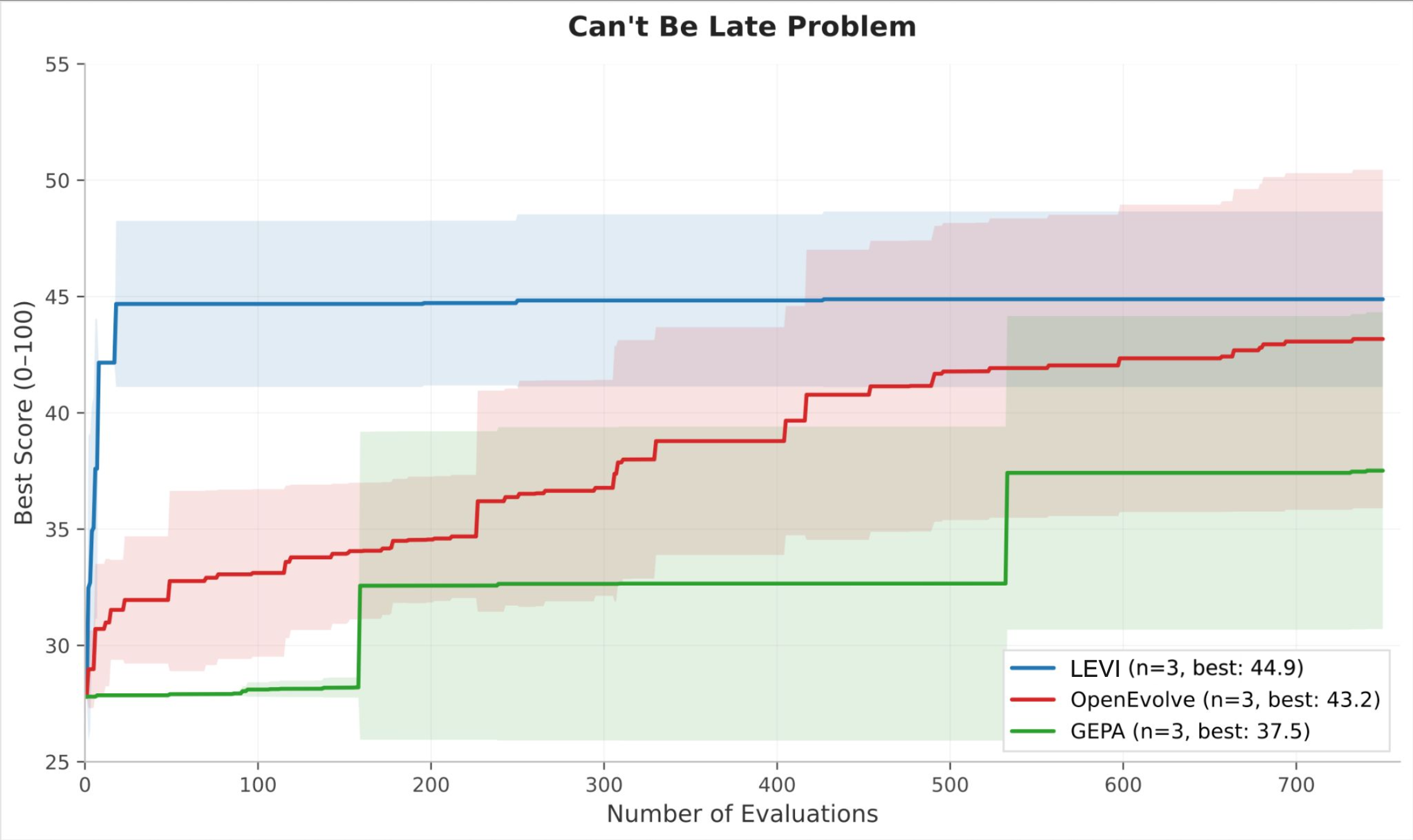
Can't Be Late, same controlled setup. LEVI reaches near-peak by eval 50, roughly 12x faster than OpenEvolve.
Same model, same budget: the performance gains come from the search architecture, not model choice. A 30B model under LEVI matches or exceeds what the same model achieves under alternative selection mechanisms.
Lessons and Looking Forward
Working with smaller models surfaces real tradeoffs that frameworks built around frontier models never have to confront:
- Higher error rates, but cheaper retries. Smaller models produce broken code more often, but the calls are so cheap that you can afford many more attempts and still come out ahead on total spend.
- Reward hacking. Smaller models are more susceptible to exploiting evaluator weaknesses rather than genuinely solving the problem. But this is an evaluator problem as much as a model problem, and fixing evaluators benefits every framework.
- Code over text. When expressing a useful idea for a smaller model to work with, code beats natural language. A prompt saying “try simulated annealing” leaves enormous room for interpretation; a code skeleton implementing the acceptance criterion and cooling schedule gives the model something concrete. This is why LEVI’s paradigm shift step generates code skeletons rather than text suggestions.
- Quantity vs. eval time. The core advantage of smaller models is volume: as shown above, more cheap calls can outperform fewer expensive ones. But this advantage depends on evaluations being fast. For problems where a single eval takes an hour, every call is precious and larger models become more sensible. LEVI mitigates this for most problems through an async distributed producer-consumer model, but for long-eval domains this is a different dimension of tradeoff worth considering.
More benchmarks and domains are in progress. ADRS is a first validation, not the full story. Try LEVI at github.com/ttanv/levi.
Quickstart
Install LEVI and run your first optimization in under 2 minutes.
Prerequisites: Python 3.11+ and uv.
git clone https://github.com/ttanv/levi.git
cd levi
uv sync
Set your API key:
export OPENAI_API_KEY="sk-..."
Create a file my_run.py:
import levi
def score_fn(pack):
bins = pack([4, 8, 1, 4, 2, 1], 10)
wasted = sum(10 - sum(b) for b in bins)
return {"score": max(0.0, 100.0 - wasted)}
result = levi.evolve_code(
"Optimize bin packing to minimize wasted space",
function_signature="def pack(items, bin_capacity):",
score_fn=score_fn,
model="openai/gpt-4o-mini",
budget_dollars=2.0,
)
print(f"Best score: {result.best_score}")
print(result.best_program)
Run it:
uv run python my_run.py
That’s a complete LEVI program. Here’s what each piece does:
problem_description— Natural language description of the optimization goal. This is injected into LLM prompts.function_signature— The Python function signature LEVI will evolve (e.g.,"def pack(items, bin_capacity):").score_fn— Your evaluation function. It receives the evolved callable and must return a dict with at least{"score": float}. Higher is better.model— The LLM to use, in LiteLLM format.budget_dollars— Maximum dollar spend. LEVI tracks cost in real-time and stops when the budget is hit.
Understanding the Result
evolve_code() returns a LeviResult:
| Field | Type | Description |
|---|---|---|
best_program |
str |
The highest-scoring code found |
best_score |
float |
Its score |
total_evaluations |
int |
Total evaluations run |
total_cost |
float |
Total dollars spent |
archive_size |
int |
Number of distinct solutions in the final archive |
runtime_seconds |
float |
Wall-clock time |
score_history |
list[float] \| None |
Score progression over time |
For a self-contained example that uses local models and needs no dataset, run examples/circle_packing/run.py.
Local Models
Why LEVI + Local Models
Most LLM-guided optimization frameworks couple performance to model capability. Drop to a cheaper model and results collapse. LEVI is different: it decouples performance from model size through its architecture.
The key insight is stratified model allocation:
- Mutation models (the workhorse) handle the bulk of code generation. These can be small, fast, and free. Think Qwen3-30B on your own GPU or MiMo-v2-Flash on OpenRouter at fractions of a cent.
- Paradigm models (the creative spark) are used periodically (every ~10 generations) to propose fundamentally new algorithmic approaches. This is the only place where a stronger model helps, and it’s called infrequently.
This means you can run LEVI with a local model doing 95% of the work and only pay for occasional cloud calls. On the ADRS benchmark, this configuration achieves the highest scores of any framework at 3–7x lower cost.
LEVI on $4.50 (local Qwen + cloud Gemini Flash) outperforms frameworks spending $15–30 with frontier models like Gemini 3 Pro and o3.
Setting Up a Local Model
Serve a model locally with vLLM, ollama, or any OpenAI-compatible server:
# vLLM example
vllm serve Qwen/Qwen3-30B-A3B-Instruct-2507 --port 8000
# ollama example
ollama serve # default port 11434
ollama pull qwen3:30b
Then tell LEVI where it is via local_endpoints:
result = levi.evolve_code(
"Optimize bin packing to minimize wasted space",
function_signature="def pack(items, bin_capacity):",
score_fn=score_fn,
mutation_model="Qwen/Qwen3-30B-A3B-Instruct-2507",
paradigm_model="openrouter/google/gemini-3-flash-preview",
local_endpoints={
"Qwen/Qwen3-30B-A3B-Instruct-2507": "http://localhost:8000/v1"
},
budget_dollars=1.0,
)
local_endpoints maps a model name to an OpenAI-compatible API base URL. The name you use here is the same name you pass to mutation_model or paradigm_model.
Mixing Local and Cloud
The recommended setup for cost-efficient runs:
result = levi.evolve_code(
problem_description,
function_signature=sig,
score_fn=score_fn,
# Cheap local model for the bulk of mutations
mutation_model="Qwen/Qwen3-30B-A3B-Instruct-2507",
# Cloud model for periodic paradigm shifts only
paradigm_model="openrouter/google/gemini-3-flash-preview",
local_endpoints={
"Qwen/Qwen3-30B-A3B-Instruct-2507": "http://localhost:8000/v1"
},
budget_dollars=1.0,
pipeline=levi.PipelineConfig(
n_llm_workers=8, # Saturate the local GPU
n_eval_processes=8,
),
)
You can also use multiple mutation models for load balancing:
mutation_model=[
"Qwen/Qwen3-30B-A3B-Instruct-2507", # local
"openrouter/mimo-v2-flash", # cloud, very cheap
],
local_endpoints={
"Qwen/Qwen3-30B-A3B-Instruct-2507": "http://localhost:8000/v1"
},
LEVI automatically creates sampler-model pairs for each mutation model at multiple temperatures (0.3, 0.7, 1.0, 1.2), so it explores a range of creativity levels.
Dollar Budget Tracking for Local Models
If you’re using dollar budgets with local models, tell LEVI the cost so it can track spend:
model_info={
"Qwen/Qwen3-30B-A3B-Instruct-2507": {
"input_cost_per_token": 0.0000001,
"output_cost_per_token": 0.0000002,
}
},
Without model_info, local model calls count as $0. You can still use budget_evals or budget_seconds as your stopping criterion instead.
Prompt Optimization for Smaller Models
Smaller models benefit significantly from optimized prompts. LEVI integrates DSPy’s MIPROv2 optimizer to automatically tune the instructions given to your mutation and paradigm shift prompts:
result = levi.evolve_code(
...,
mutation_model="Qwen/Qwen3-30B-A3B-Instruct-2507",
paradigm_model="openrouter/google/gemini-3-flash-preview",
local_endpoints={"Qwen/Qwen3-30B-A3B-Instruct-2507": "http://localhost:8000/v1"},
prompt_opt=levi.PromptOptConfig(enabled=True),
budget_dollars=4.50,
)
When prompt_opt is enabled, LEVI runs a short optimization phase before evolution begins. It generates candidate instruction variants, tests them against your scoring function, and picks the best. Results are cached, so subsequent runs skip this step.
Enable prompt optimization whenever you're using local or small models. It typically adds 1–3 minutes of setup time but can measurably improve final scores. See examples/ADRS/cant_be_late/run.py for a working example.
Architecture
Why LEVI Is Faster
Most LLM-guided optimization frameworks run sequentially: generate a candidate, evaluate it, update the population, repeat. This means the LLM sits idle while code evaluates, and the evaluator sits idle while the LLM generates.
LEVI uses an async producer-consumer pipeline that runs LLM generation and code evaluation concurrently:
┌─────────────────────────────────────────────────────────┐
│ Async Event Loop │
│ │
│ ┌─ LLM Producers (n_llm_workers) ──────────┐ │
│ │ Producer 1: sample archive → call LLM ───┐ │
│ │ Producer 2: sample archive → call LLM ───┤ │
│ │ Producer 3: sample archive → call LLM ───┤ code │
│ │ ... ├──queue──┐│
│ └───────────────────────────────────────────┘ ││
│ ││
│ ┌─ Eval Consumers (n_eval_processes) ───────┐ ││
│ │ Consumer 1: evaluate → update archive ◄─┤ ││
│ │ Consumer 2: evaluate → update archive ◄─┤◄─────────┘│
│ │ Consumer 3: evaluate → update archive ◄─┤ │
│ │ ... │ │
│ └───────────────────────────────────────────┘ │
│ │
│ Budget tracker (real-time cost, evals, time) │
└─────────────────────────────────────────────────────────┘
While one candidate is being evaluated, others are being generated. While the LLM is thinking, evaluations are running. Nothing waits.
On the ADRS benchmark, LEVI converges to top scores in a fraction of the wall-clock time.
Each evaluation runs in its own subprocess via ResilientProcessPool, providing:
- Isolation — a candidate that crashes or loops doesn’t take down the pipeline
- Hard timeouts — stuck evaluations are terminated after
eval_timeoutseconds - True parallelism — evaluations run on separate CPU cores, not just async tasks
Tuning Parallelism
pipeline=levi.PipelineConfig(
n_llm_workers=8, # Concurrent LLM generation tasks
n_eval_processes=8, # Concurrent evaluation subprocesses
eval_timeout=60.0, # Kill evaluations that take longer
)
Guidelines:
n_llm_workers: For cloud APIs, 4–8 is usually optimal (rate limits are the bottleneck). For local models, increase to saturate your GPU — try 8–16.n_eval_processes: Match to your CPU core count. Each evaluation runs in a separate process.eval_timeout: Default 60s. Increase for problems with slow evaluations (e.g., 300–600s for complex simulations).
Balancing Producers and Consumers
What matters is the balance between generation and evaluation. If either side runs too far ahead, candidates are generated from a stale archive instead of building on recent results.
- Too many LLM workers: the queue fills with candidates derived from the same archive state — redundant work that burns budget without progress.
- Too many eval processes: evaluators block on slow scores while the archive stagnates — new generations can’t learn from recent results either.
Start with n_llm_workers ≈ n_eval_processes, then skew toward whichever side is the bottleneck (more LLM workers for slow APIs, more eval processes for slow scoring).
Solving Custom Problems
Defining Your Problem
Every LEVI run requires three things:
1. Problem description — A natural language description injected into LLM prompts. Be specific about constraints, objectives, and edge cases:
problem_description = """
Optimize a function that schedules jobs on machines to minimize makespan.
Each job has a processing time and a deadline. Jobs cannot be split across
machines. Minimize the time at which all jobs are complete.
"""
2. Function signature — The Python function that LEVI will evolve. Must be a valid def statement:
function_signature = "def schedule(jobs, n_machines):"
3. Score function — Your evaluation logic. Receives the evolved callable and returns a dict with at least {"score": float}:
def score_fn(schedule):
result = schedule(TEST_JOBS, 4)
makespan = max(end_time for _, end_time in result)
return {"score": max(0.0, 1000.0 - makespan)}
You can also return additional metrics that LEVI can use for diversity and reporting:
def score_fn(schedule):
result = schedule(TEST_JOBS, 4)
makespan = max(end_time for _, end_time in result)
utilization = sum(busy for busy, _ in result) / (makespan * 4)
return {
"score": max(0.0, 1000.0 - makespan),
"utilization": utilization,
"deadline_violations": count_violations(result),
}
If your scoring function needs test inputs, pass them via inputs:
result = levi.evolve_code(
...,
score_fn=score_fn,
inputs=TEST_INPUTS, # score_fn(fn, inputs) will be called
)
Not sure how to phrase your problem description? LEVI has built-in prompt optimization that can refine your description automatically. See the Prompt Optimization section under Local Models.
Behavioral Features
LEVI maintains a behavioral archive (CVT-MAP-Elites) that keeps structurally diverse solutions alive, preventing the search from converging on a single approach. It does this by mapping each evolved program to a point in behavior space based on code structure features.
Default features work well for general code optimization:
| Feature | What it captures |
|---|---|
loop_count |
Number of loops (for/while) |
branch_count |
Number of if statements |
math_operators |
Density of arithmetic operations |
loop_nesting_max |
Deepest nested loop level |
For domain-specific problems, you’ll want to choose features that capture meaningful variation in your problem:
Using Score Keys for Diversity
If your score_fn returns multiple metrics, you can use them as diversity dimensions. This is the easiest and most powerful way to customize diversity:
# Your score function returns sub-metrics
def score_fn(fn):
return {
"score": overall_score,
"tight_deadline_score": tight_score,
"loose_deadline_score": loose_score,
}
# Tell LEVI to use those metrics for diversity
result = levi.evolve_code(
...,
behavior=levi.BehaviorConfig(
ast_features=["cyclomatic_complexity", "branch_count"],
score_keys=["tight_deadline_score", "loose_deadline_score"],
),
)
Now the archive will maintain solutions that excel on different sub-problems, not just different code structures.
Choosing AST Features
All 14 built-in AST features:
| Feature | Description |
|---|---|
code_length |
Character count |
ast_depth |
Maximum AST depth |
cyclomatic_complexity |
McCabe complexity |
loop_count |
For/while loop count |
branch_count |
If statement count |
loop_nesting_max |
Maximum loop nesting depth |
math_operators |
Arithmetic operator count |
function_def_count |
Number of function definitions |
numeric_literal_count |
Number of numeric literals |
comparison_count |
Number of comparisons |
subscript_count |
Array indexing operations |
call_count |
Function call count |
comprehension_count |
List/dict/set comprehensions |
range_max_arg |
Largest argument to range() |
Pick features that you expect to vary between meaningfully different solutions to your problem. For example:
- For a sorting algorithm:
comparison_count,subscript_count,loop_nesting_max - For a scheduling heuristic:
cyclomatic_complexity,branch_count,math_operators - For a numerical method:
math_operators,numeric_literal_count,loop_count
Custom Extractors
For features that can’t be captured by AST analysis, use custom extractors:
def extract_algorithm_family(program):
"""Classify by algorithmic approach."""
code = program.content
if "heapq" in code or "heap" in code:
return 1.0
elif "sorted" in code or "sort" in code:
return 2.0
elif "deque" in code or "queue" in code:
return 3.0
return 0.0
result = levi.evolve_code(
...,
behavior=levi.BehaviorConfig(
ast_features=["loop_count", "branch_count"],
custom_extractors={"algorithm_family": extract_algorithm_family},
),
)
Guiding the Search
Seed program — Provide a working (even naive) starting implementation. LEVI generates diverse variants from it during initialization:
result = levi.evolve_code(
...,
seed_program="""
def schedule(jobs, n_machines):
# Simple greedy: assign each job to the least loaded machine
loads = [0] * n_machines
assignment = []
for job in sorted(jobs, key=lambda j: -j.time):
min_machine = min(range(n_machines), key=lambda m: loads[m])
loads[min_machine] += job.time
assignment.append((min_machine, job))
return assignment
""",
)
Paradigm shifts — For problems where you suspect multiple viable algorithmic families (greedy, dynamic programming, metaheuristic), keep punctuated equilibrium enabled (it is by default). This periodically uses the paradigm model to propose entirely new approaches:
punctuated_equilibrium=levi.PunctuatedEquilibriumConfig(
enabled=True,
interval=10, # Every 10 evaluations
n_clusters=3, # Find 3 distinct solution clusters
n_variants=3, # Generate 3 variants per paradigm shift
)
Inspirations — Control how many existing solutions are shown to the LLM when generating mutations:
pipeline=levi.PipelineConfig(
n_parents=1, # Primary parent to mutate
n_inspirations=1, # Additional solutions shown for cross-pollination
)
Core Concepts
Programs — LEVI evolves Python functions. Each candidate is a Program containing the code string, a unique ID, and metadata.
Scoring — Your score_fn evaluates each candidate. It must return {"score": float} where higher is better. Additional keys are used for diversity and reporting.
Archive (CVT-MAP-Elites) — The population is stored in a behavioral archive: a grid of cells where each cell holds the single best solution with that behavioral profile. This prevents convergence by forcing the population to maintain structural diversity. The archive uses Centroidal Voronoi Tessellation (CVT) to partition behavior space into n_centroids cells (default: 50).
Stratified Models — Mutation models handle the bulk of code generation (cheap, fast). Paradigm models are used only for periodic “paradigm shifts” that propose fundamentally new approaches (stronger, infrequent).
Samplers — The archive uses multiple sampling strategies to select parents for mutation:
- Softmax — Temperature-weighted sampling by fitness (higher temperature = more exploration)
- UCB — Upper Confidence Bound balances exploration and exploitation
- Uniform — Pure random selection
- Per-subscore — Samples the best solution for each secondary metric
Meta-Advice — LEVI analyzes failure patterns (crashes, timeouts, invalid code) and generates lessons that are injected into future LLM prompts. This helps the search avoid repeating mistakes.
Budget — LEVI tracks spend across all parallel workers in real-time. You can set limits on dollars, evaluations, wall-clock time, or target score (stop when reached). Multiple constraints can be combined.
Configuration Reference
evolve_code()
The main entry point. All arguments after problem_description are keyword-only.
result = levi.evolve_code(
problem_description: str,
*,
function_signature: str,
seed_program: str | None = None,
score_fn: Callable[..., dict],
inputs: list[Any] | None = None,
model: str | list[str] | None = None,
paradigm_model: str | list[str] | None = None,
mutation_model: str | list[str] | None = None,
budget_dollars: float | None = None,
budget_evals: int | None = None,
budget_seconds: float | None = None,
target_score: float | None = None,
resume_snapshot: dict | None = None,
**kwargs, # Any LeviConfig field
) -> LeviResult
Model selection — Pass model for a single model doing everything, or paradigm_model/mutation_model for separate models. Cannot mix both.
Budget — At least one of budget_dollars, budget_evals, or budget_seconds is required. Multiple can be combined (AND logic — stops when any is hit).
kwargs — Any LeviConfig field can be passed directly: pipeline, behavior, punctuated_equilibrium, prompt_opt, local_endpoints, model_info, output_dir, etc.
BudgetConfig
| Parameter | Type | Default | Description |
|---|---|---|---|
dollars |
float \| None |
None |
Maximum dollar spend |
evaluations |
int \| None |
None |
Maximum number of evaluations |
seconds |
float \| None |
None |
Maximum wall-clock seconds |
target_score |
float \| None |
None |
Stop when this score is reached |
PipelineConfig
| Parameter | Type | Default | Description |
|---|---|---|---|
n_llm_workers |
int |
4 |
Concurrent LLM generation tasks |
n_eval_processes |
int |
4 |
Concurrent evaluation subprocesses |
eval_timeout |
float |
60.0 |
Timeout per evaluation (seconds) |
temperature |
float \| None |
None |
Override LLM temperature for mutations |
max_tokens |
int |
16384 |
Maximum LLM output tokens |
n_parents |
int |
1 |
Parent programs sampled for mutation |
n_inspirations |
int |
1 |
Additional programs shown for inspiration |
output_mode |
str |
"full" |
"full" (complete code) or "diff" (SEARCH/REPLACE blocks) |
BehaviorConfig
| Parameter | Type | Default | Description |
|---|---|---|---|
ast_features |
list[str] |
["loop_count", "branch_count", "math_operators", "loop_nesting_max"] |
AST-based code structure features for diversity |
score_keys |
list[str] |
[] |
Secondary score metrics to use as diversity dimensions |
init_noise |
float |
0.0 |
Noise added during initialization normalization |
custom_extractors |
dict[str, Callable] |
{} |
Custom feature extractors: name -> fn(program) -> float |
CVTConfig
| Parameter | Type | Default | Description |
|---|---|---|---|
n_centroids |
int |
50 |
Number of cells in the behavioral archive |
defer_centroids |
bool |
True |
Build centroids from initial behavior data (recommended) |
InitConfig
| Parameter | Type | Default | Description |
|---|---|---|---|
enabled |
bool |
True |
Run the initialization phase |
n_diverse_seeds |
int |
4 |
Number of diverse starting programs to generate |
n_variants_per_seed |
int |
20 |
Variants generated per seed |
diversity_model |
str \| None |
None |
Auto-filled from paradigm_models[0] |
variant_models |
list[str] \| None |
None |
Auto-filled from mutation_models |
temperature |
float \| None |
None |
Temperature override for init |
diversity_prompt |
str \| None |
None |
Custom prompt for diverse seed generation |
diversity_llm_kwargs |
dict |
{} |
Extra LLM kwargs (e.g., reasoning_effort, max_tokens) |
PunctuatedEquilibriumConfig
Periodic paradigm shifts using heavier models to escape local optima.
| Parameter | Type | Default | Description |
|---|---|---|---|
enabled |
bool |
True |
Enable periodic paradigm shifts |
interval |
int |
10 |
Trigger every N evaluations |
n_clusters |
int |
3 |
Cluster archive into N behavioral regions |
n_variants |
int |
3 |
Variants generated per paradigm shift |
heavy_models |
list[str] \| None |
None |
Auto-filled from paradigm_models |
variant_models |
list[str] \| None |
None |
Auto-filled from mutation_models |
behavior_noise |
float |
0.0 |
Noise applied to behavior vectors |
temperature |
float \| None |
None |
Temperature override |
reasoning_effort |
str \| None |
None |
Model-specific reasoning effort (e.g., "high" for o1/o3) |
MetaAdviceConfig
Learns from evaluation failures and injects lessons into future prompts.
| Parameter | Type | Default | Description |
|---|---|---|---|
enabled |
bool |
True |
Enable the meta-advice system |
interval |
int |
50 |
Generate advice every N evaluations |
model |
str \| None |
None |
Auto-filled from mutation_models[0] |
max_tokens |
int |
400 |
Maximum advice length |
temperature |
float \| None |
None |
Temperature override |
CascadeConfig
Two-stage evaluation: quick filter first, full evaluation only for promising candidates.
| Parameter | Type | Default | Description |
|---|---|---|---|
enabled |
bool |
True |
Enable cascade evaluation |
quick_inputs |
list[Any] |
[] |
Fast test cases for quick evaluation |
min_score_ratio |
float |
0.8 |
Threshold: skip full eval if quick score < best × ratio |
quick_timeout |
float |
30.0 |
Timeout for quick evaluations (seconds) |
PromptOptConfig
DSPy MIPROv2-based prompt optimization. Runs before evolution.
| Parameter | Type | Default | Description |
|---|---|---|---|
enabled |
bool |
False |
Enable prompt optimization |
teacher_model |
str \| None |
None |
Model for MIPROv2 proposals. Auto-filled from paradigm_models[0] |
n_trials |
int |
12 |
Optimization trials |
num_candidates |
int |
4 |
Candidates per trial |
num_threads |
int |
4 |
Parallel optimization threads |
init_temperature |
float |
1.2 |
Initial instruction temperature |
optimize_mutation |
bool |
True |
Optimize mutation prompts |
optimize_paradigm_shift |
bool |
True |
Optimize paradigm shift prompts (only if PE is enabled) |
cache_dir |
str \| None |
None |
Cache location (defaults to output_dir) |
force |
bool |
False |
Re-optimize even if cached results exist |
SamplerModelPair
Fine-grained control over sampler strategy and model pairing. Auto-generated from mutation_models if not provided.
| Parameter | Type | Default | Description |
|---|---|---|---|
sampler |
str |
required | Sampler name: "softmax", "ucb", "uniform", "per_subscore", "cyclic_annealing" |
model |
str |
required | LLM model identifier |
weight |
float |
1.0 |
Weight for sampler selection (must be positive) |
temperature |
float \| None |
None |
LLM temperature for this pair |
n_cycles |
int \| None |
None |
Number of annealing cycles (for cyclic_annealing sampler) |
Example with custom pairs:
result = levi.evolve_code(
...,
sampler_model_pairs=[
levi.SamplerModelPair("softmax", "openai/gpt-4o-mini", temperature=0.3),
levi.SamplerModelPair("softmax", "openai/gpt-4o-mini", temperature=1.2),
levi.SamplerModelPair("ucb", "openai/gpt-4o-mini", weight=0.5),
],
budget_dollars=5.0,
)
LeviResult
Returned by evolve_code().
| Field | Type | Description |
|---|---|---|
best_program |
str |
Highest-scoring code found |
best_score |
float |
Its score |
total_evaluations |
int |
Total evaluations run |
total_cost |
float |
Total dollars spent |
archive_size |
int |
Number of elites in the final archive |
runtime_seconds |
float |
Wall-clock time |
score_history |
list[float] \| None |
Score progression over time |
Advanced Features
Snapshots and Resume
LEVI auto-saves snapshots every 10 evaluations to {output_dir}/snapshot.json. To resume a previous run:
import json
with open("runs/20260301_120000/snapshot.json") as f:
snapshot = json.load(f)
result = levi.evolve_code(
...,
resume_snapshot=snapshot,
budget_dollars=5.0, # Additional budget for this run
)
Set output_dir to control where snapshots are saved:
result = levi.evolve_code(
...,
output_dir="runs/my_experiment",
)
Sampler Strategies
By default, LEVI auto-generates softmax sampler pairs at 4 temperatures (0.3, 0.7, 1.0, 1.2) for each mutation model. You can customize this:
- Softmax — Temperature-weighted sampling by fitness. Low temperature (0.3) exploits top solutions; high temperature (1.2) explores broadly.
- UCB — Upper Confidence Bound. Automatically balances exploration and exploitation based on which archive cells have been productive.
- Uniform — Pure random selection. Ensures every cell gets sampled eventually.
- Per-subscore — Samples the best solution for each secondary metric (
score_keys). Useful when your problem has multiple objectives. - Cyclic Annealing — Temperature oscillates between high and low over the budget, creating periodic exploration/exploitation phases.
Cascade Evaluation
If your full evaluation is expensive, use cascade evaluation to quickly filter unpromising candidates:
result = levi.evolve_code(
...,
cascade=levi.CascadeConfig(
enabled=True,
quick_inputs=SMALL_TEST_SET, # Fast test cases
min_score_ratio=0.8, # Skip if quick score < 80% of best
quick_timeout=30.0,
),
inputs=FULL_TEST_SET, # Full evaluation for survivors
)
Examples
Circle Packing (Local Models, Self-Contained)
Optimize the packing of 26 circles into a unit square. No dataset needed. Uses a local Qwen model for mutations and cloud Gemini Flash for paradigm shifts.
cd examples/circle_packing
uv run python run.py
ADRS Benchmark Problems
Seven problems from the ADRS Leaderboard covering cloud scheduling, GPU placement, broadcast optimization, SQL generation, and more.
| Problem | Key Config Feature | Budget |
|---|---|---|
cant_be_late |
Prompt optimization, custom score_keys |
$4.50 |
cant_be_late_multi |
Init + prompt opt + paradigm shifts | $4.50 |
prism |
Standard config | $4.50 |
llm_sql |
Standard config | $4.50 |
cloudcast |
Standard config | $4.50 |
eplb |
Standard config | $4.50 |
txn_scheduling |
Higher budget, complex evaluation | $8.72 |
cd examples/ADRS/prism
uv run python run.py
Common Patterns
Cloud-only, simplest possible:
result = levi.evolve_code(
problem, function_signature=sig, score_fn=scorer,
model="openai/gpt-4o-mini",
budget_dollars=5.0,
)
Local + cloud, cost-optimized:
result = levi.evolve_code(
problem, function_signature=sig, score_fn=scorer,
mutation_model="Qwen/Qwen3-30B-A3B-Instruct-2507",
paradigm_model="openrouter/google/gemini-3-flash-preview",
local_endpoints={"Qwen/Qwen3-30B-A3B-Instruct-2507": "http://localhost:8000/v1"},
budget_dollars=4.50,
pipeline=levi.PipelineConfig(n_llm_workers=8, n_eval_processes=8),
)
Fully-loaded (all features):
result = levi.evolve_code(
problem, function_signature=sig, score_fn=scorer,
seed_program=my_seed, inputs=test_inputs,
mutation_model=["Qwen/Qwen3-30B-A3B-Instruct-2507", "openrouter/mimo-v2-flash"],
paradigm_model="openrouter/google/gemini-3-flash-preview",
local_endpoints={"Qwen/Qwen3-30B-A3B-Instruct-2507": "http://localhost:8000/v1"},
budget_dollars=4.50,
pipeline=levi.PipelineConfig(n_llm_workers=12, n_eval_processes=12, eval_timeout=300),
behavior=levi.BehaviorConfig(
ast_features=["cyclomatic_complexity", "comparison_count", "math_operators", "branch_count"],
score_keys=["tight_deadline_score", "loose_deadline_score"],
),
prompt_opt=levi.PromptOptConfig(enabled=True),
output_dir=f"runs/my_experiment",
)
Troubleshooting
Common Errors
OPENAI_API_KEY not set — Set your API key as an environment variable:
export OPENAI_API_KEY="sk-..."
# For OpenRouter models:
export OPENROUTER_API_KEY="sk-or-..."
Must specify 'model' or 'paradigm_model'/'mutation_model' — You need to provide at least one model. Pass model= for a single model, or paradigm_model=/mutation_model= for separate models.
Must specify at least one budget constraint — Pass at least one of budget_dollars, budget_evals, or budget_seconds.
Evaluation timeouts — If you see many timeout errors, increase eval_timeout:
pipeline=levi.PipelineConfig(eval_timeout=300)
Local model connection refused — Verify your local model server is running and the URL matches local_endpoints. Test with:
curl http://localhost:8000/v1/models
Rate limit errors — Reduce n_llm_workers to lower concurrent API requests:
pipeline=levi.PipelineConfig(n_llm_workers=4)
Performance Tips
- Use local models for mutations. This is the single biggest cost optimization. A local Qwen3-30B handles mutations well.
- Enable prompt optimization for small models (
prompt_opt=levi.PromptOptConfig(enabled=True)). - Increase
n_llm_workersfor local models to saturate your GPU. - Match
n_eval_processesto your CPU core count. - Use
score_keysif your problem has natural sub-objectives — this gives LEVI better diversity signal. - Try
budget_evalsinstead ofbudget_dollarswhen using free local models.