LEVI: Stronger Search Architectures Can Substitute for Larger LLMs
A harness-first evolutionary framework for code and prompt optimization. Better scores than frontier-model runs of GEPA, OpenEvolve, ShinkaEvolve, AdaEvolve, and EvoX, at 3.3–6.7× lower cost.
Most LLM-guided evolutionary systems get their results the expensive way: by pointing a frontier model at the problem and burning through hundreds or thousands of expensive calls. LEVI takes the opposite bet, that a stronger search architecture can substitute for a larger model and drastically reduce the cost. Fix the harness so the archive preserves diverse solutions instead of the model, route mutations to the model that actually fits the job, and stop re-scoring redundant examples, and strong results follow even from small open-source models at a fraction of the budget.
This holds across two very different settings:
- Code optimization. On systems-research benchmarks, LEVI beats the best published frontier-budget runs of GEPA, OpenEvolve, ShinkaEvolve, AdaEvolve, and EvoX on six of seven problems, at 3.3–6.7× lower cost.
- Prompt optimization. On four GEPA-suite benchmarks, LEVI matches or exceeds GEPA using less than half the rollouts.
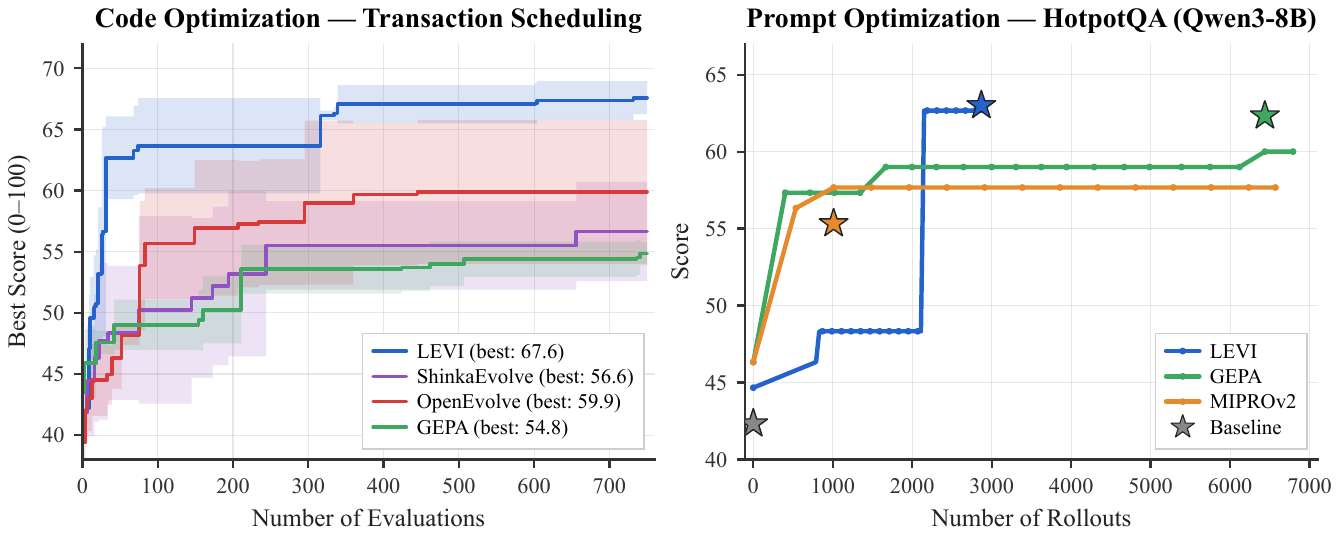
LEVI reaches higher final performance using a fraction of the budget. Left: on Transaction Scheduling code optimization, LEVI exceeds every baseline's final score within the first ~50 evaluations (≈15× sample efficiency). Right: on HotpotQA prompt optimization with Qwen3-8B, LEVI outperforms GEPA with fewer than half the rollouts (~2.75K vs ~6.87K).
Why this is a harness problem, not a model problem
Frontier-model dependence is largely an artifact of how existing frameworks allocate search, not a fundamental requirement.
LLM-guided evolution pairs a language model with a search loop: the user provides a problem and a scoring function, the LLM mutates candidate solutions, an evaluator scores them, and a solution database keeps the promising ones around. The paradigm was introduced by FunSearch11 FunSearch (Romera-Paredes et al., 2024) produced novel mathematical results, including the cap-set improvement, without a frontier-scale model. and scaled up by AlphaEvolve,22 AlphaEvolve (Novikov et al., 2025) extended the loop to stronger LLMs and larger codebases. and it now spans math, code optimization, heuristic design, systems research, and prompt optimization.
The catch is cost. A single run can require thousands of calls to expensive frontier models, and reported systems-research runs often cost $15–30 per problem on GPT-5 or Gemini 3.0 Pro. That price raises the barrier to entry and slows iteration. But it is not obviously inherent to the paradigm; FunSearch produced its results without a frontier model at all. We argue the cost comes from over-relying on larger models while under-investing in the search architecture, and it shows up along three separate axes:
- Per-evaluation. When the archive fails to preserve diversity, the search collapses into a single basin and leans on a strong model to generate escapes. Existing frameworks patch this after the fact with islands, embedding-based novelty filters, or LLM judges, each compensating for convergence rather than preventing it.
- Per-dollar. Mutation calls are treated uniformly, so frontier-model prices get paid even for local edits a small model could handle.
- Per-rollout. Every candidate is re-scored on the full validation set, spending rollouts on redundant examples, which is especially painful in prompt optimization.
LEVI fixes all three. Rather than building the harness around the assumption of a strong model, we ask what the search architecture should look like when the budget is limited.
LEVI
Three components, one per cost axis: a diversity-preserving solution database, a role-aware mutation router, and a rank-preserving proxy benchmark.
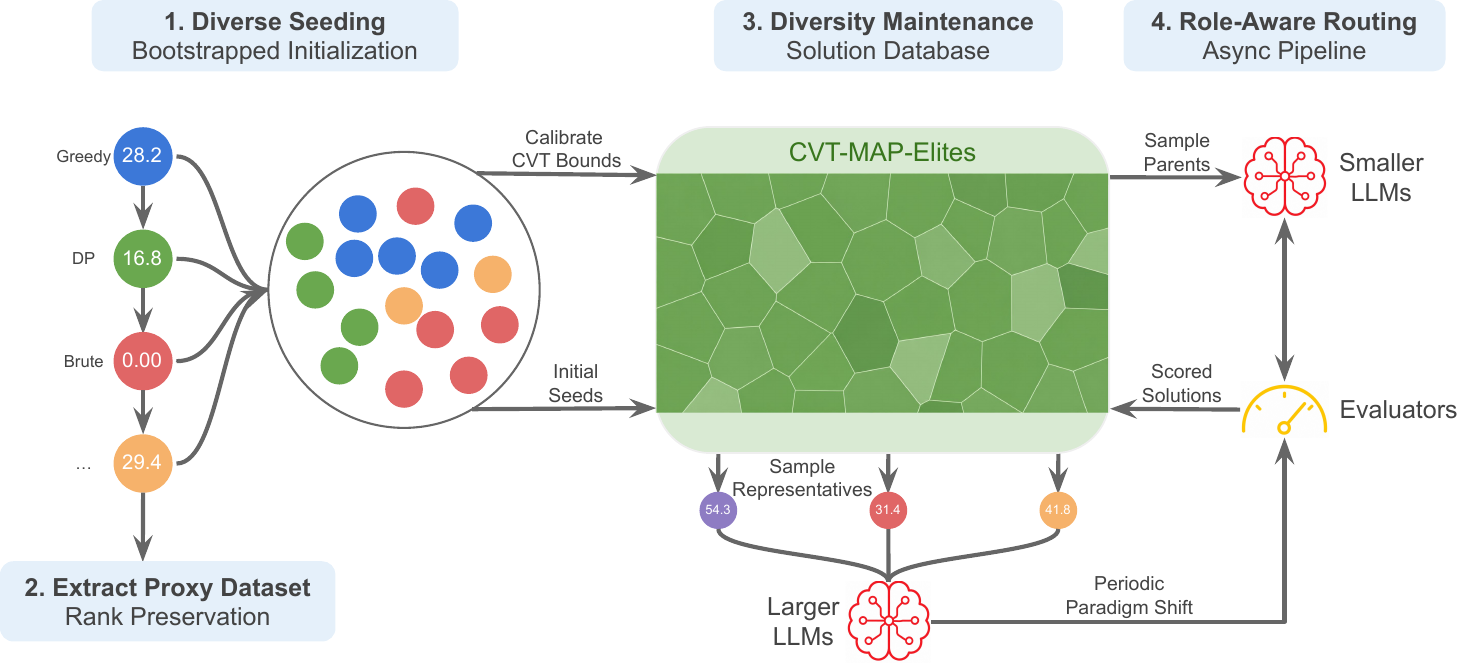
LEVI uses one bootstrapped seed pass to initialize solution families, calibrate the CVT-MAP-Elites database, and build the proxy benchmark. During search, the archive feeds an asynchronous mutation–evaluation loop: most mutations use a small LLM for local refinement, while periodic paradigm shifts use a stronger LLM to propose structurally new candidates.
LEVI follows an asynchronous AlphaEvolve-style loop. The solution database stores evaluated candidates, samplers draw parents from it, the router sends mutation requests to the appropriate model, and resulting candidates are evaluated in parallel before being inserted back. Parents are sampled with a softmax over scores, with worker-specific temperatures balancing exploration and exploitation across the parallel pool. The three pieces below are best read as extensions of each other: the archive provides the structure that makes principled routing possible, and principled routing is what makes a diversity-preserving archive practical under a tight budget.
A solution database that establishes diversity early and maintains it
Diverse seeding plus a CVT-MAP-Elites archive with flexible behavioral dimensions.
A useful archive must establish diversity early and preserve it throughout. Most frameworks begin from a single seed program, which means the early search spends budget escaping one basin of attraction, and later diversity has to be recovered through ad-hoc mechanisms. LEVI makes a small upfront investment instead. During initialization it asks the LLM for a sequence of structurally diverse seeds, each conditioned on previous attempts and explicitly instructed to differ from them, with failures fed back so the next seed avoids dead ends. Weak-but-distinct seeds are kept on purpose: they expand the observed descriptor range and provide footholds in regions local mutation rarely reaches.
The same seed pass calibrates the archive. LEVI uses a CVT-MAP-Elites archive,33 CVT-MAP-Elites (Vassiliades et al., 2017) replaces the regular MAP-Elites grid with a centroidal Voronoi tessellation, scaling to higher-dimensional descriptor spaces without exponential cell growth. mapping each candidate to a behavioral descriptor, assigning it to the nearest centroid in a Voronoi tessellation, and keeping only the highest-scoring candidate per cell. Descriptor values are normalized online (Welford z-score plus a sigmoid), so high-variance dimensions do not dominate the geometry, and the running statistics update as new behavioral regimes appear.
Crucially, LEVI supports two descriptor families and accepts any mix. Input-side descriptors come from the solution itself (code length, AST features like cyclomatic complexity, loop and operator counts) and are useful when outputs are sparse. Output-side descriptors come from execution behavior (runtime, per-instance score profiles) and expose trade-offs between examples, which matters for prompt optimization. Existing frameworks commit to one family; OpenEvolve and ShinkaEvolve to input-side features, GEPA implicitly to output-side ones through its per-instance Pareto front. LEVI chooses the mix that fits the problem.
Role-aware LLM routing
Cheap models for the local edits that dominate the run; a stronger model reserved for rare structural jumps.
Mutation calls look uniform from the outside, but the work varies enormously. Most are local refinements, tweak a constant, swap a data structure, inline a helper. A few are structural rewrites that change the algorithm’s shape. Existing frameworks pay frontier-model prices for both, implicitly assuming mutation quality scales with model size across the board. We argue the two operations have different requirements: local refinement rewards speed and volume, where smaller models suffice; structural rewrites reward the broader prior coverage that comes with scale.
LEVI splits this into two routes. The refinement route sends roughly 90% of mutation calls to a small model such as Qwen3-30B-A3B, drawing parents from the archive and asking for a single targeted edit. Small models can collapse onto common patterns, but the archive absorbs this: near-duplicate outputs map to occupied cells and are discarded, so collapse pressure becomes harmless redundancy rather than archive drift. The paradigm-shift route is where the larger model earns its cost. Instead of asking it to edit one strong parent, LEVI samples high-scoring representatives from distinct, well-separated archive cells and passes them together, asking for a candidate that belongs to none of those families. The model operates on the structure of the population, not a single parent, extending the frontier of explored families. These calls fire at fixed intervals and on stagnation.
The routes are complementary: refinement deepens the cells the archive already occupies, paradigm shifts expand the set of cells worth occupying. The optimal split is problem-dependent, and the archive ties both together, giving the small model robustness to its own redundancy and giving the large model a structural view a single-parent prompt cannot.
A rank-preserving proxy benchmark
When evaluation cost dominates, score on a small subset chosen to preserve candidate rankings, not every individual score.
The third axis appears when evaluating a candidate is itself expensive. In code optimization, the dominant cost is usually the mutation call or the program run. In prompt optimization, each candidate prompt may require many rollouts across a validation set, and prior work spends a large fraction of its budget there. LEVI builds a smaller proxy benchmark, a subset of the full discovery set, that preserves the selection signal of the full set, since evolutionary selection only depends on choosing better candidates over worse ones, not on exact scores.
The proxy is built during the same initialization pass: each diverse seed is scored on every example in the discovery set, producing a calibration matrix of how candidate quality varies across examples. LEVI then greedily selects a subset that maximizes three terms, rank faithfulness (does the subset’s induced candidate ranking agree with the full set), separation (does the example discriminate between candidates), and a redundancy penalty (is this example’s score column already correlated with chosen ones). On a 24-prompt × 150-problem matrix this greedy column-subset method beats k-medoids and random-subset + ridge regression at every iso-cost contour.
Results
Systems-research benchmarks at a fraction of the cost, a controlled same-model comparison, ablations isolating each component, and prompt optimization.
Systems research, against frontier-budget baselines
We evaluate on seven tasks from the ADRS problem suite44 ADRS (Cheng et al., 2025): real-world systems problems spanning networking, LLM serving, databases, and distributed systems. spanning networking, LLM serving, databases, and distributed systems. Baselines are the strongest published results from GEPA,55 GEPA (Agrawal et al., 2025), OpenEvolve, and ShinkaEvolve (Lange et al., 2025). Baseline runs use GPT-5 or Gemini 3.0 Pro at $15–30 per problem. OpenEvolve, ShinkaEvolve, AdaEvolve, and EvoX, each coupled with expensive budgets and SOTA models. LEVI instead spends under $5 on most problems, routing more than 90% of mutations to a Qwen3-30B and a MiMo-v2-Flash, with the rest going to Gemini 3.0 Flash for paradigm shifts.
| Framework | Cloudcast ↓ | EPLB ↑ | LLM-SQL ↑ | Prism ↑ | Txn Sched ↑ | Spot-M ↑ | Spot-S ↑ |
|---|---|---|---|---|---|---|---|
| GEPA | 645.72 | 0.1445 | 0.7134 | 26.23 | 3984.1 | 62.2 | 51.4 |
| OpenEvolve | 707.82 | 0.1272 | 0.7258 | 26.24 | 4273.5 | 66.7 | 42.5 |
| ShinkaEvolve | 812.74 | 0.1272 | 0.7212 | 26.26 | 4329.0 | 63.6 | 45.6 |
| AdaEvolve | 637.10 | 0.1453 | 0.7750 | 26.37 | 4348.0 | — | — |
| EvoX | 623.69 | 0.1453 | 0.7300 | 26.26 | 4347.83 | — | — |
| LEVI | 578.10 | 0.1523 | 0.7985 | 26.26 | 4464.29 | 72.4 | 51.7 |
| Baseline budget | $15 | $15 | $20 | $15 | $20 | $25 | $30 |
| LEVI budget | $4.50 | $4.50 | $4.50 | $4.50 | $12.50 | $4.50 | $4.50 |
LEVI improves on the best published result on six of seven native metrics. The lone exception is Prism, where every frontier-budget method clusters within 0.14 points. On six problems LEVI spends $4.50, a 3.3–6.7× cost reduction; on Transaction Scheduling, an extended $12.50 run still sits below the $20 frontier-model budget while beating the prior best by a wide margin. On LLM-SQL, LEVI passes the leading framework after spending only $0.50, a 35× cost reduction.
Controlled comparison: same model, same budget
The table above mixes model choice, budget, and architecture. To isolate the search architecture, we run LEVI, OpenEvolve, ShinkaEvolve, and GEPA under identical conditions: a single Qwen3-30B-A3B model, 750 evaluations, and three random seeds, on two complementary problems. Transaction Scheduling is a single-output NP-hard ordering task; Spot Scheduling is scored across 1,080 simulations, giving Pareto-style methods a richer signal.
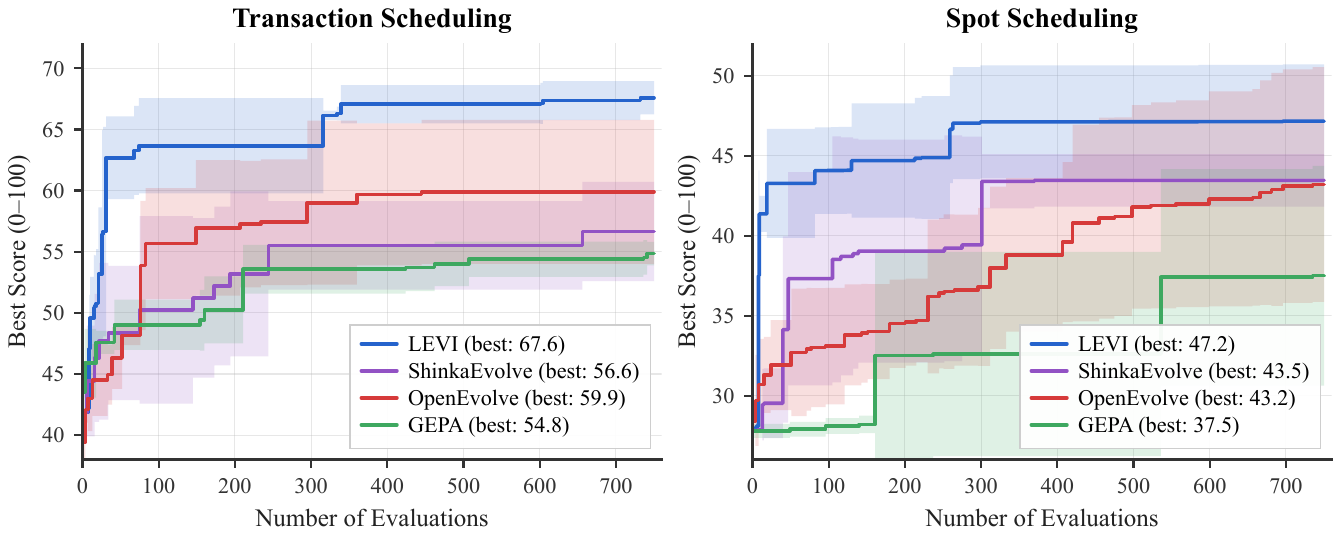
Same model, same budget, three seeds (mean ± std). LEVI reaches high scores much earlier on both problems and finishes highest, despite identical model access. On Spot Scheduling it reaches near-peak by ~50 evaluations where OpenEvolve needs 600+ (≈12× sample efficiency); on Transaction Scheduling it hits 62 within 100 evaluations, a level no baseline reaches at any point.
The baselines plateau early, consistent with converging onto a single algorithmic family, while LEVI keeps improving through the middle of the run as the calibrated archive sustains exploration past the first discovered family. The performance gains are attributable to the search architecture, not model choice or budget.
Ablations
Removing the bootstrapped seeds has the largest single effect. On Transaction Scheduling the final score falls from 68.3 to 62.8; on Spot Scheduling the variant stalls near the un-optimized baseline (42.3 vs 50.2), essentially flat from evaluation 100 onward. The richer diversity dimensions are problem-dependent: they match the simpler set on Transaction Scheduling, which stays dominated by one conflict-aware-greedy family, but win by ~5 points on Spot Scheduling, where several algorithmic families need to be maintained at once.
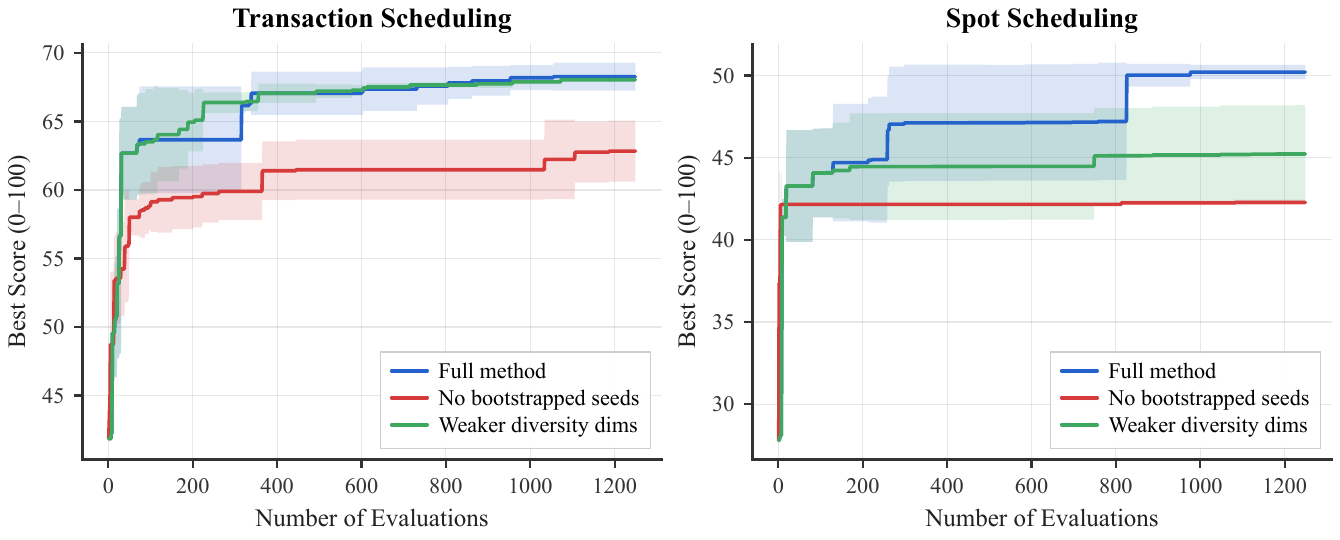
Solution-database ablation. Bootstrapped initialization drives rapid early improvement; strong diversity dimensions keep the archive from converging when multiple families matter.
Model allocation tells a complementary story, and it is where the harness-first thesis is sharpest: larger models help only when structural jumps are actually needed. On Transaction Scheduling, dominated by local refinement within one family, removing the large model entirely slightly beats full LEVI (67.4 vs 64.7), since paradigm-shift calls are pure overhead there. Spot Scheduling is intermediate; all variants reach ~50–52 but LEVI gets there first. EPLB is where paradigm shifts decisively earn their cost: the no-large-models variant stagnates at 57.2 with structurally identical elites, while full LEVI reaches 63.9 by discovering families the small model never finds, and matches the no-large-models endpoint at roughly 5× lower cost.
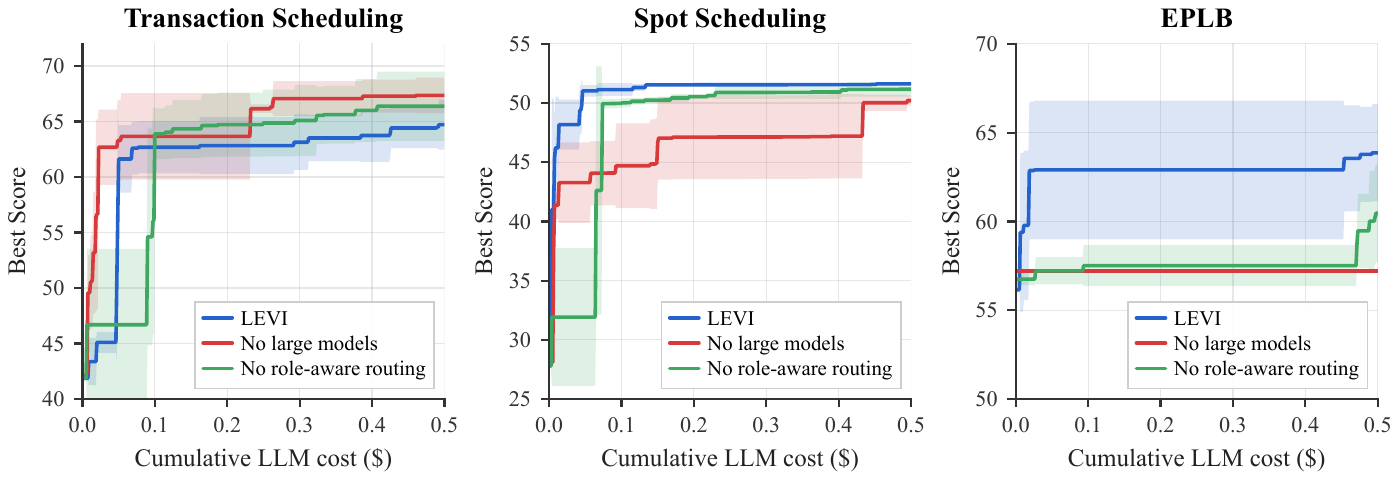
Model-allocation ablation versus cumulative LLM cost. Larger models hurt in the local-refinement regime (Transaction Scheduling) and decisively help where structural jumps are needed (EPLB).
Prompt optimization
The same archive and routing machinery transfer to prompt optimization unchanged, with the proxy benchmark doing the heavy lifting on cost. We evaluate on four GEPA-suite benchmarks with Qwen3-8B as the task model, optimizing the same DSPy program so only the prompts differ, and measure cost in total rollouts.
| Qwen3-8B | HotpotQA | IFBench | Hover | PUPA | Aggregate | Improvement |
|---|---|---|---|---|---|---|
| Baseline | 42.33 | 36.90 | 35.33 | 80.82 | 48.85 | — |
| MIPROv2 | 55.33 | 36.22 | 47.33 | 81.55 | 55.11 | +6.26 |
| GEPA | 62.33 | 38.61 | 52.33 | 91.85 | 61.28 | +12.44 |
| LEVI | 63.00 | 46.33 | 49.00 | 89.73 | 62.02 | +13.17 |
| GEPA rollouts | 6871 | 3593 | 7051 | 2426 | 4985 | — |
| LEVI rollouts | 2750 | 1870 | 2870 | 1275 | 2191 | — |
LEVI takes the highest aggregate score while spending less than half of GEPA’s rollout budget (2,191 vs 4,985 averaged across tasks). It matches GEPA on HotpotQA, improves substantially on IFBench (+7.72), and stays competitive on Hover and PUPA. Per-task rollout ratios land in the 40–53% range, so the efficiency advantage holds uniformly rather than coming from one benchmark.
Takeaways
The cost reductions are not the point; they are evidence that the harness-first bet works. When the archive preserves diversity by construction, a cheap model suffices for most of the search, and a stronger model is needed only for the rare moments that actually require it. The three components each address a different regime, and the ablations show none is universally dominant: seeding and descriptors preserve useful diversity, role-aware routing trades local refinement against structural jumps, and proxy benchmarks preserve the ranking signal selection depends on.
LEVI still reserves a small fraction of calls for a frontier model, and shifting work onto cheap mutations can require more evaluations, a favorable trade when evaluations are cheap but less so when each takes hours. Studying regimes that rely entirely on cheap open-weight models is a natural next step.
LEVI is open-source. Point it at a scoring function and a seed program, and it runs until the budget is spent.